2020 年 9 月 2 日凌晨,RTX 30 系列显卡发布,新一代 Titan 正式命名为 RTX 3090,拥有高达 10496 个 CUDA Core,同时还搭载了第 2 代 RT Core 和 第 3 代 Tensor Core。等等,什么是 CUDA Core,它和流处理器有什么关系?RT Core 和 Tensor Core 又是干嘛的?为什么说老黄刀功精湛?拥有显示功能的芯片这么多,显卡/独显/核显/集显/GPU/APU 有什么区别?
拥有显示功能的芯片们
显卡(Video Card/Display Card/Graphics Card):个人电脑的基础组成部分之一,计算和转换计算机需要显示的信息,提供扫描信号并控制显示器正确显示。
GPU(Graphics Processing Unit,图形处理器):显卡的核心,它与显存、PCB 等一同组成显卡。
APU(Accelerated Processing Unit,加速处理器):是 AMD 公司的处理器品牌。AMD 公司在并购 ATI 公司后,公布了代号为 AMD Fusion 的项目,目标是在一块芯片上集成传统的 CPU 和 GPU。AMD 提供半客制化 APU 服务,广为人知的例子就是 PS4 和 Xbox One 采用了客制化 APU。
独显:独立显卡(External Video Card),由 GPU、显存、PCB 等组成,需要插在主板对应的接口上。一般语境下的显卡便是指独显。
集显:集成显卡( Integrated Video Card),集成在主板的北桥芯片上,没有独立显存,需要占用内存。已淘汰。
核显:核芯显卡,是 Intel 公司于 2010 年推出的显示核心 HD Graphics 的中文品牌名称,其高端系列为 Iris Graphics。它集成于 CPU 中,没有独立显存,需要占用内存。Intel 将北桥的功能集成在 CPU 上,包括集显,这种设计是为了回应 AMD Fusion 项目。
产品线
NVIDIA
NVIDIA 公司的产品线最为丰富,从用于移动设备的 Tegra,到消费级的 GeForce,再到专业级的 Quadro,还有数据中心使用的 Tesla,遍布游戏、设计、深度计算等各个领域。下文也围绕 NVIDIA 的 GeForce 系列产品的相关技术进行介绍。
- GeForce:消费级产品,用于个人电脑,一般用来打游戏。
- Quadro:专业级产品,用于工作站,用在计算机辅助设计和数字内容创作等特定行业。
- Tegra:SoC 产品,用于移动设备,比如 Nintendo Switch。
- Tesla:高性能计算(HPC)产品,用于数据中心的服务器,用来进行深度学习。
AMD
- Radeon:消费级产品。
- Radeon Pro:用于工作站和高性能计算。
Intel
Intel 公司的显示芯片集成在 CPU 中,一般用来点亮屏幕。
- HD Graphics:普通核显。
- Iris (Pro) Graphics:最高端的核显。
显卡核心架构
命名
众所周知,NVIDIA 近些年喜欢以物理学家的名字对显卡的核心架构进行命名,如 Pascal(帕斯卡,GeForce 10 系列),Volta(伏特,无 GeForce 系列产品),Turing(图灵,GeForce 20 系列)、Ampere(安培,GeForce 30 系列)。

代号与产品
近些年 NVIDIA 推出了不同架构、不同核心的多款产品,这里只列举 GeForce、Quadro 和 Tesla 三个系列的桌面端产品:
| 代号 | 新特性 | 核心代号 | 产品 |
|---|---|---|---|
| Pascal | GP100 | Tesla P100, Quadro GP100 | |
| GP102 | TITAN X(p), GTX 1080 Ti, Tesla P40, Quadro P6000 | ||
| GP104 | GTX 1080, GTX 1070(Ti), GTX 1060(GDDR5X), Tesla P6/P4, Quadro P5000/P4000 | ||
| GP106 | GTX 1060, Quadro P2200/2000 | ||
| GP107 | GTX 1050(Ti), Quadro P1000/P620/P600/P400 | ||
| GP108 | GTX 1030 | ||
| Volta | 为深度学习设计的 Tensor Core | GV100 | TITAN V(CEO Edition), Tesla V100, Quadro GV100 |
| Turing | 用于光线追踪的 RT core,借助 Tensor Core 实现 DLSS | TU102 | TITAN RTX, RTX 2080 Ti, Quadro RTX 8000/6000 |
| TU104 | RTX 2080(Super), RTX 2070 Super, Tesla T4, Quadro RTX 5000/4000 | ||
| TU106 | RTX 2070, RTX 2060(Super) | ||
| 阉割了 RT Core 和 Tensor Core | TU116 | GTX 1660(Ti/Super), GTX 1650 Super | |
| TU117 | GTX 1650 | ||
| Ampere | 第 2 代 RT Core,第 3 代 Tensor Core,全新 SM | GA100 | Tesla A100 |
| GA102 | RTX 3090, RTX 3080 | ||
| GA104 | RTX 3070 |
可以看出,每一代架构一般都设计了多种不同的核心,以代号进行区分,同时每种核心又对应多种产品。
硬件架构
GP100架构
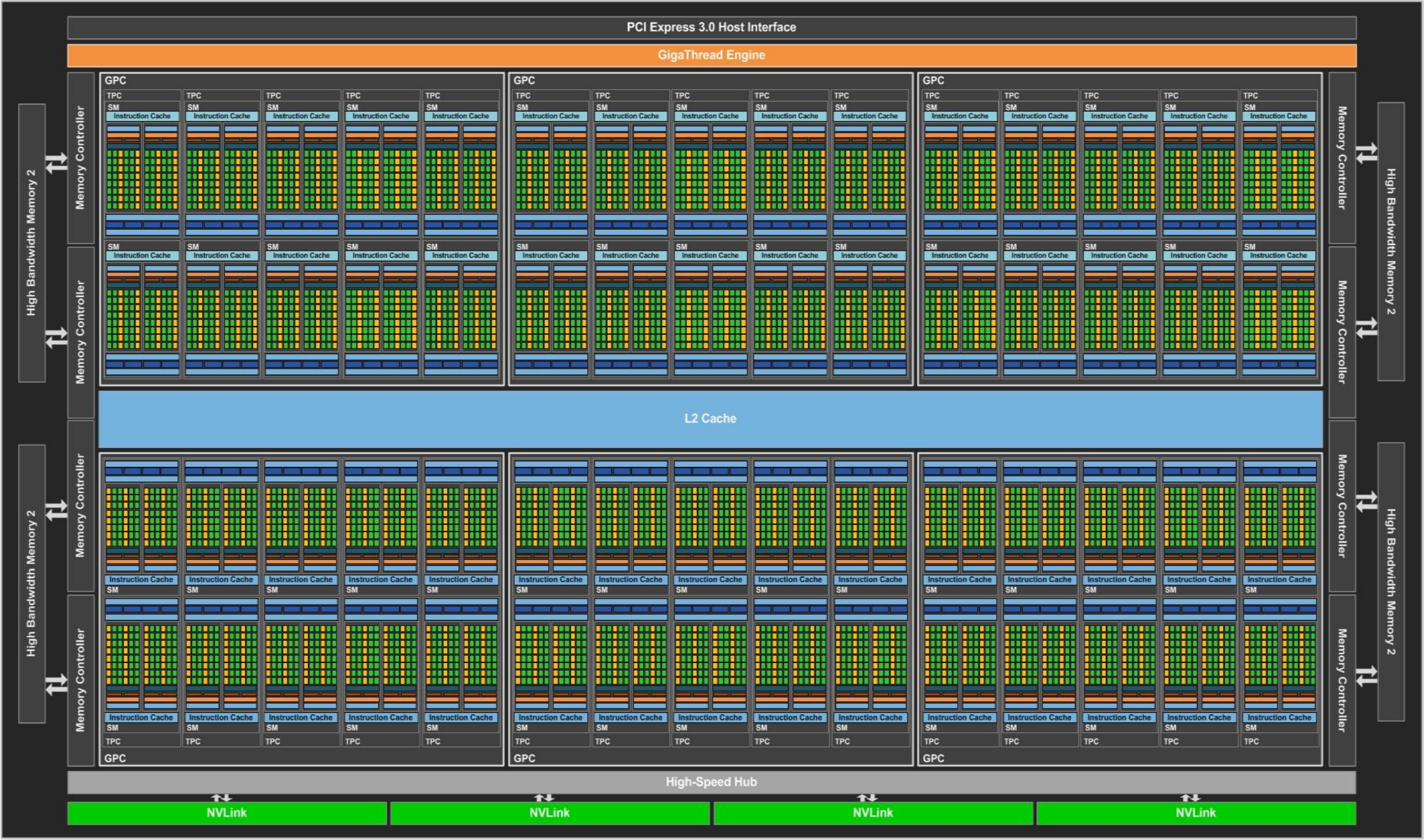

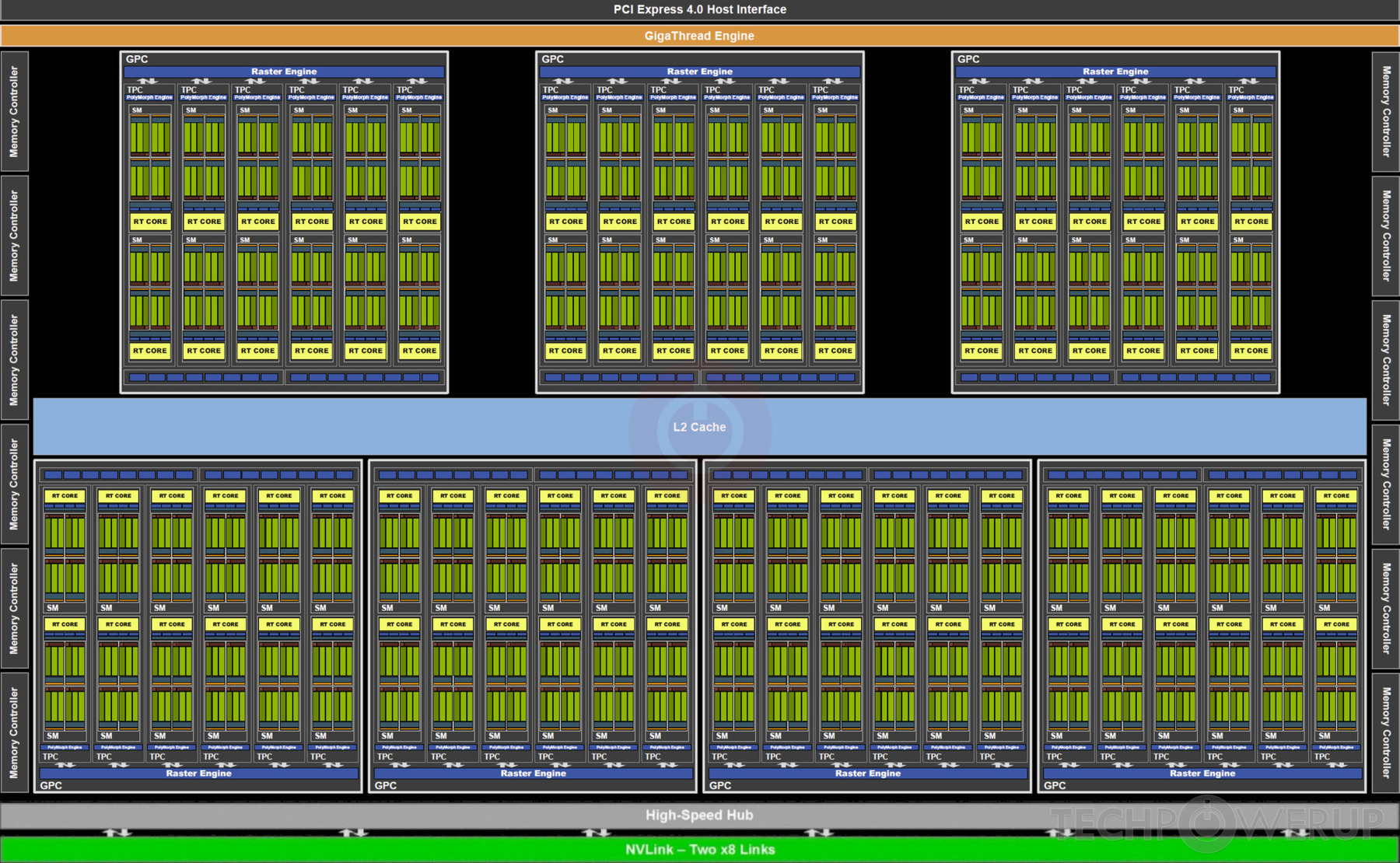
完整的 GP100 GPU 包含 6 个 GPC(Graphics Processing Cluster,图形处理集群),每个 GPC 包含 5 个 TPC(Texture Processing Cluster,纹理处理集群),每个 TPC 包含 2 个 SM(Streaming Multiprocessor,流多处理器)。
SM 里面绿色的 Core 便是 CUDA Core,也就是我们常说的 SP(Streaming Processor,流处理器);黄色的 DP Unit(Double Precision Unit,双精度单元)是用来进行双精度浮点计算的;LD/ST(Load Store Unit,载入储存单元)是用来操作内存的;SFU(Special Function Unit,特殊运算单元)负责特殊的 ALU 运算,如 SIN 和 COS。
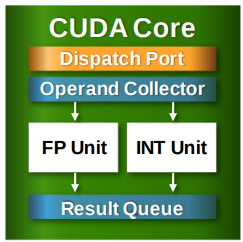
每个 CUDA Core 由控制单元(Dispatch Port 和 Operand Collector)、浮点计算单元(FP Unit)、整数计算单元(INT Unit)以及计算结果队列组成。
衡量 GPU 性能的重要指标是浮点计算能力。单精度浮点数采用 4 个字节(32 位)来表达一个数字,双精度浮点数采用 8 个字节(64 位)来表达一个数字,此外还有半精度浮点数(16 位)。对于数字范围大而且需要精确计算的科学计算来说,要求采用双精度浮点数;对于常见的多媒体和图形处理计算,单精度浮点数已经足够了;而对于一些要求精度更低的机器学习等应用来说,半精度浮点数就够用了。
可以看出,在 GP100 这个 Pascal 系列最专业的核心中,计算单精度浮点数的 FP Unit 和计算双精度浮点数的 DP Unit 的数量之比为 2:1,而在消费级产品中,更是砍掉了计算双精度浮点数的 DP Unit。
GV100架构

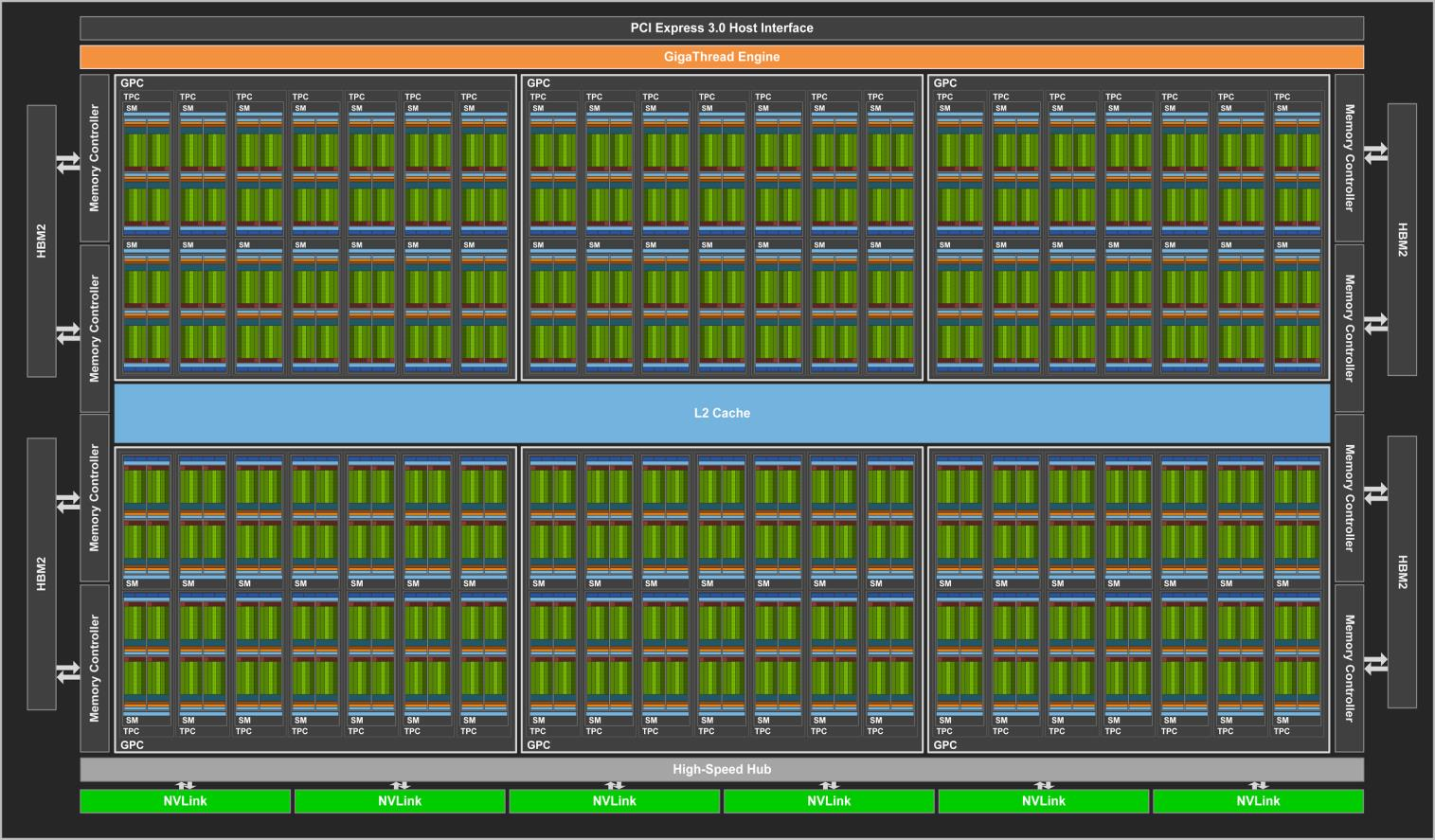
完整的 GV100 GPU 包含 6 个 GPC,每个 GPC 包含 7 个 TPC,每个 TPC 包含 2 个 SM,每个 SM 包含 64 个 FP32 核心(计算单精度浮点数)、32 个 FP64 核心(计算双精度浮点数)、64 个 INT32 核心(计算整数)、8 个 Tensor 核心、4 个纹理单元。
Tensor Core 的首次亮相便是在 Volta 架构中,第一代 Tensor Core 专为深度学习而设计,通过 FP16 和 FP32 下的混合精度矩阵乘法提供了突破性的性能。
TU102架构

![TU102-Block Diagram]](/GPU/TU102-Block Diagram.png)
完整的 TU102 GPU 包含 6 个 GPC,每个 GPC 包含 6 个 TPC,每个 TPC 包含 2 个 SM,每个 SM 包含 64 个 CUDA Core 和 8 个 Tensor Core。
Tensor Core 是专门为执行张量/矩阵运算而设计的专用执行单元,这些运算是深度学习中使用的核心计算功能。第二代 Tensor Core 首次为 GeForce 带来了基于深度学习的新 AI 功能——DLSS。DLSS(Deep Learning Super Sampling,深度学习超级采样)利用深度神经网络来提取渲染场景的多维特征,并智能地组合多个帧中的细节以构建高质量的最终图像。
在现代游戏中,渲染的帧并非直接显示,而是要先对其执行后期处理图像增强步骤。在此步骤中,将来自多个渲染帧的输入组合在一起,可以在保留细节的同时,消除诸如锯齿等视觉失真现象。例如,随机采样抗锯齿(TAA)是一种基于着色器的算法,使用运动矢量组合两帧,以确定在何处对前一帧进行采样。 然而这种图像增强过程从根本上来说很难正确实行。对于这类没有清晰算法解决方案的图像分析和优化问题可通过应用 AI 来完美解决。DLSS 通过消除细节,能够以更低的输入样本数更快地渲染,这意味 DLSS 得到的画质与传统渲染方式相差无几,但性能更高。
Turing 引入了实时光线追踪功能,该功能使单个 GPU 可以渲染视觉逼真的 3D 游戏和有着精确阴影、反射和折射的复杂专业模型。 RT Core 用于加快光线追踪,可提供实时光线追踪体验。
GA100架构

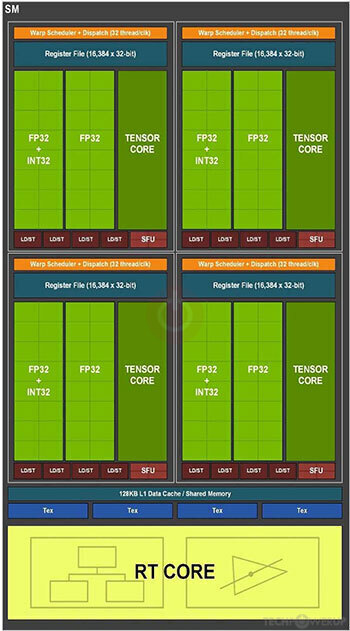
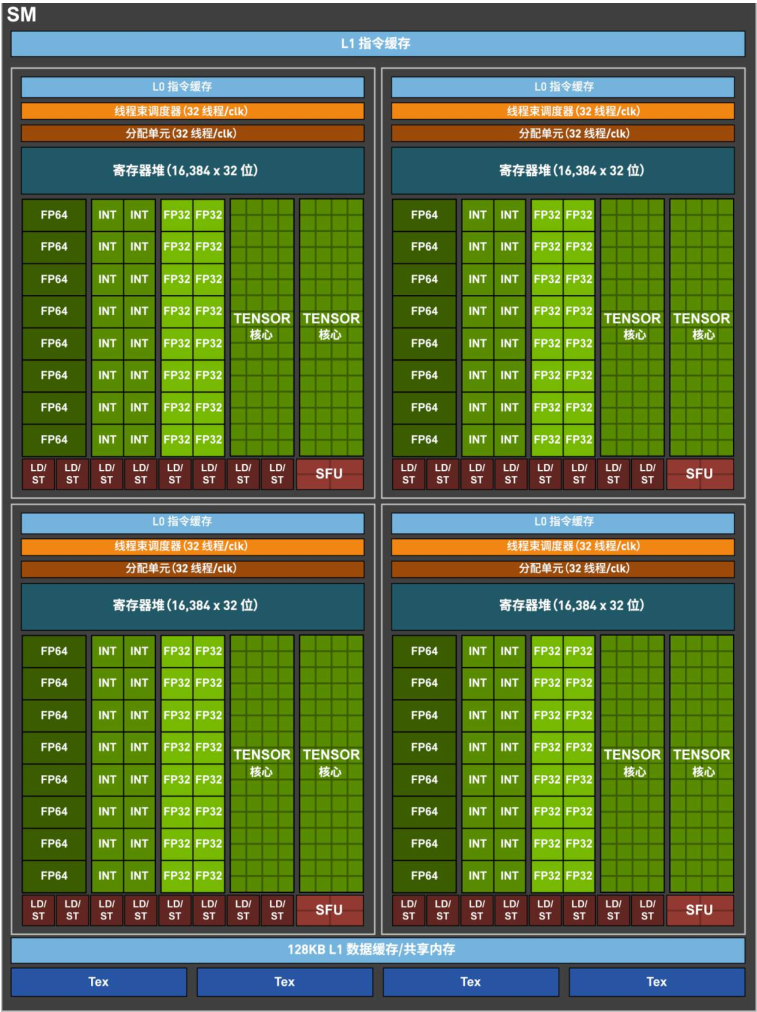
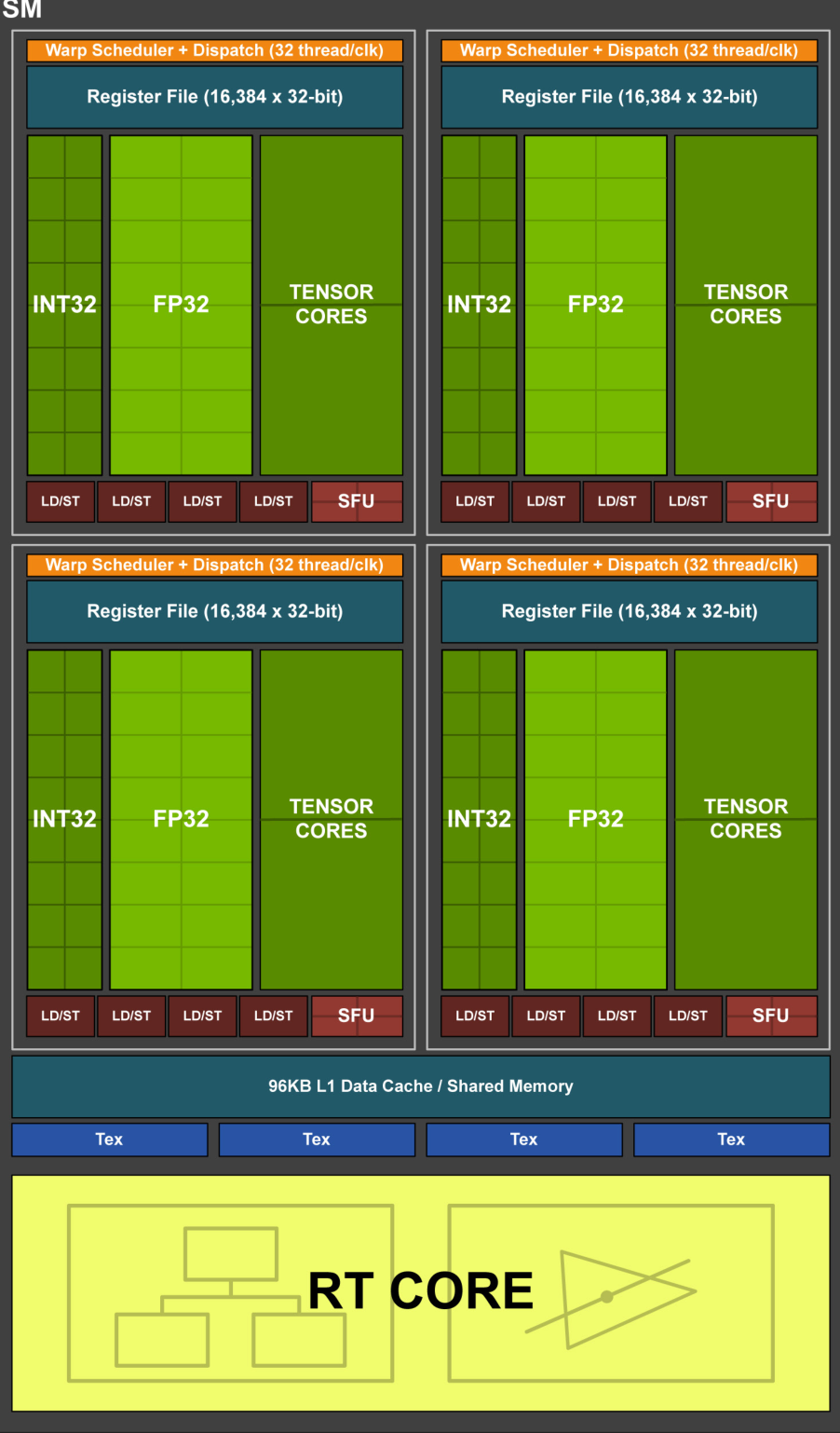
RTX 3090 的 TU102 GPU 包含 7 个 GPC,每个 GPC 包含 6 个 TPC(其中某个 GPC 的 1 个 TPC 被屏蔽了),每个 TPC 包含 2 个 SM,每个 SM 包含 128 个 CUDA Core 和 4 个 Tensor Core。
在新的架构中,给 SM 每个分区中的 INT32 整数计算单元处添加了 FP32 浮点计算单元,使得这部分计算单元可以切换工作状态为 INT32 或 FP32,实现 FP32 操作两倍吞吐量的一设计目标。
刀法精湛
无论是 CPU 还是 GPU,同样一款核心,会根据品质不同做成不同型号的产品。也就是说,i3/i5/i7 可能是在同一条流水线上生产的,RTX 2080Ti 和 TITAN RTX 也可能出自同一片晶圆。通过调整核心的规格以及显卡的用料,可以让不同级别的产品拥有不同的性能,老黄便精于此道。

TU102 核心有以下几款产品:
- RTX TATIN:完整核心。共 72 组 SM 单元,4608 个 CUDA Core。
- RTX 2080Ti:屏蔽了 4 组 SM 单元。共 68 组 SM 单元,4352 个 CUDA Core。

TU104 核心有以下几款产品:
- RTX 2080 Super:完整核心。共 48 组 SM 单元,3072 个 CUDA Core。
- RTX 2080:屏蔽了 2 组 SM 单元。共 46 组 SM 单元,2944 个 CUDA Core。
- RTX 2070 Super:屏蔽了 8 组 SM 单元。共 40 组 SM 单元,2560 个 CUDA Core。

TU106 核心有以下几款产品:
- RTX 2070:完整核心。共 36 组 SM 单元,2304 个 CUDA Core。
- RTX 2060 Super:屏蔽了 2 组 SM 单元。共 34 组 SM 单元,2176 个 CUDA Core。
- RTX 2060:屏蔽了 6 组 SM 单元。共 30 组 SM 单元,1920 个 CUDA Core。
营销过头的CUDA
NVIDIA 出于营销的考虑,在许多技术上都冠以 CUDA 之名,因此 CUDA 在不同语境下可能有不同的含义。
CUDA与OpenCL
CUDA(Compute Unified Device Architecture,统一计算架构)是 NVIDIA 于 2006 年推出的通用并行计算架构,同时也是 GPGPU 技术中的一种主流框架。NVIDIA 提供了 SDK 和 API,允许开发者使用 CUDA C 语言开发需要通用并行计算能力的程序,只能用于 NVIDIA 的硬件中。
OpenCL(Open Computing Language,开放计算语言)是一项与 CUDA 类似的技术。与只能在 N 卡中使用 CUDA 不同,OpenCL 的功能可以被多种显卡使用,包括 A 卡和 N 卡。
CUDA Core与流处理器
CUDA Core 的数量和流处理器数量有什么关系?

NVIDIA 在介绍显卡的硬件规格时会标注出 CUDA Core 核心数,在比较不同产品纸面性能的差距时也会通过 CUDA Core 的数量来判断,其实这里的 CUDA Core 的数量就是我们以前常说的 SP(Stream Processors,流处理器)数量。
虽然每一代架构计算单元都会发生变化,但 NVIDIA 一直将 FP32 的数量作为 CUDA Core 的数量进行宣传。在工艺提升和新架构允许切换 INT32 为 FP32 的影响下,RTX 3090 实现了 CUDA Core 数量一万的突破。
CUDA与水银加速
Adobe Premiere 中的水银加速与 CUDA 之间是什么关系呢?

被我们称为“水银加速”的 Mercury Playback Engine 是 Adobe Premiere Pro CS5 及以后大量性能改进的名称。这些改进包括:
- 64 位程序。
- 多线程程序。
- 使用 CUDA 进行某些计算(OpenCL 要到 Premiere Pro CS6)。
Mercury Playback Engine 包括软件优化和硬件加速这两部分改进,不仅单指使用 CUDA/OpenCL 处理,在项目设置里也可以看到分为“GPU 加速”和“软件”。
光追性能
为了方便各大媒体制作 RTX 30 系显卡的相关评测,飞燕群岛工作室发布了 《光明记忆:无限》光线追踪 基准测试软件 ,采用了光线追踪和 DLSS 2.1 技术,支持光线追踪的 20 系显卡同样可以运行。
使用 R5 3600X + RTX 2060 Super 进行基准测试,成绩如下:
| 分辨率 | RTX质量 | DLSS | FPS |
|---|---|---|---|
| 2560x1440 | Ultra | OFF | 12 |
| 2560x1440 | Ultra | Quality | 24 |
| 2560x1440 | Ultra | Performance | 34 |
| 2560x1440 | High | Performance | 41 |
| 2560x1440 | Normal | Performance | 45 |
| 2560x1440 | Low | Performance | 54 |
| 1920x1080 | Ultra | OFF | 20 |
| 1920x1080 | Ultra | Quality | 36 |
| 1920x1080 | Ultra | Performance | 57 |
| 1920x1080 | High | Performance | 62 |
| 1920x1080 | Normal | Performance | 68 |
| 1920x1080 | Low | Performance | 81 |
点击查看测试结果截图

RTX 2060 Super 能够满足 1080p 分辨率下畅玩光追游戏的需要,但要想在 2K 分辨率下以 60 FPS 稳定运行光追游戏,至少需要 2070 及以上性能。开启光线追踪和 DLSS 运行 Ghostrunner Demo ,也得到了同样的结论。
参考资料
Nvidia GPU架构 - Cuda Core,SM,SP等等傻傻分不清?
techpowerup NVIDIA TP100
techpowerup NVIDIA TU102
techpowerup NVIDIA GA100
CUDA, OpenCL, Mercury Playback Engine, and Adobe Premiere Pro