Spark SQL is Apache Spark’s module for working with structured data.
Spark SQL 是 Spark 用来处理结构化数据的一个模块,它提供了一个编程抽象叫作 DataFrame,并且作为分布式 SQL 查询引擎。
概述
Spark SQL 是 Spark 用来处理结构化数据的一个模块,它提供了一个编程抽象叫作 DataFrame,并且作为分布式 SQL 查询引擎。Spark SQL 的核心是 Catalyst 优化器,解析 SQL 语句并优化执行。
虽然可以使用 Hive 处理结构化数据,将 HiveQL 转换成 MapReduce 程序提交到集群中去执行,但 MapReduce 这种计算模型执行效率比较慢,所以 Spark SQL 应运而生,它将 SQL 转换成 RDD 提交到集群中去执行,执行效率非常快。
DataFrame与Dataset
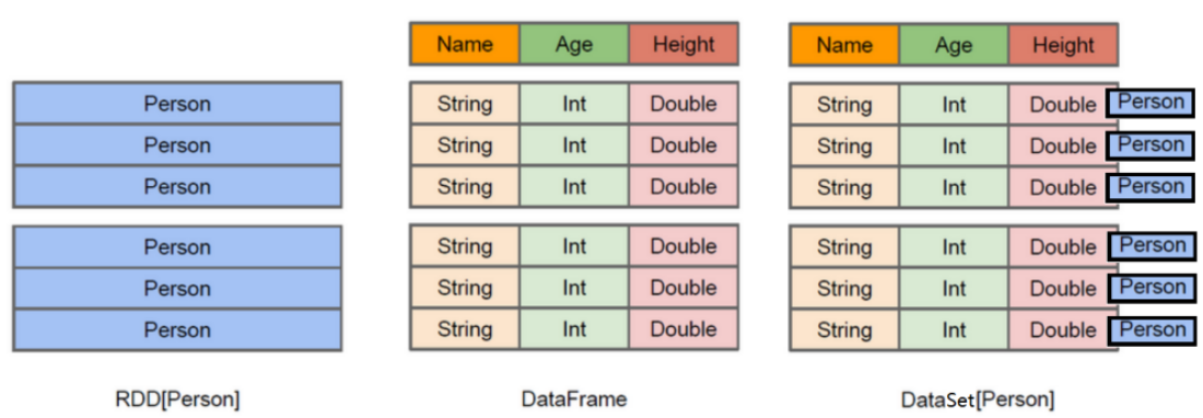
DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库的二维表格,记录了数据和数据的结构信息(RDD + Schema)。DataFrame 可以从多种数据源构建,如:结构化文件、已有的 RDD、RDBMS、Hive。
DataFrame 的前身是 SchemaRDD,DataFrame 相比 SchemaRDD 的主要区别是它不再直接继承自 RDD,而是自己实现了 RDD 的绝大多数功能,但仍然可以在 DataFrame 上调用 rdd() 方法将其转换为一个 RDD。
DataSet是在 Spark 1.6 中添加的新接口。与 RDD 相比,保存了更多的描述信息,概念上等同于关系型数据库中的二维表;与 DataFrame 相比,保存了类型信息,是强类型的,提供了编译时类型检查。
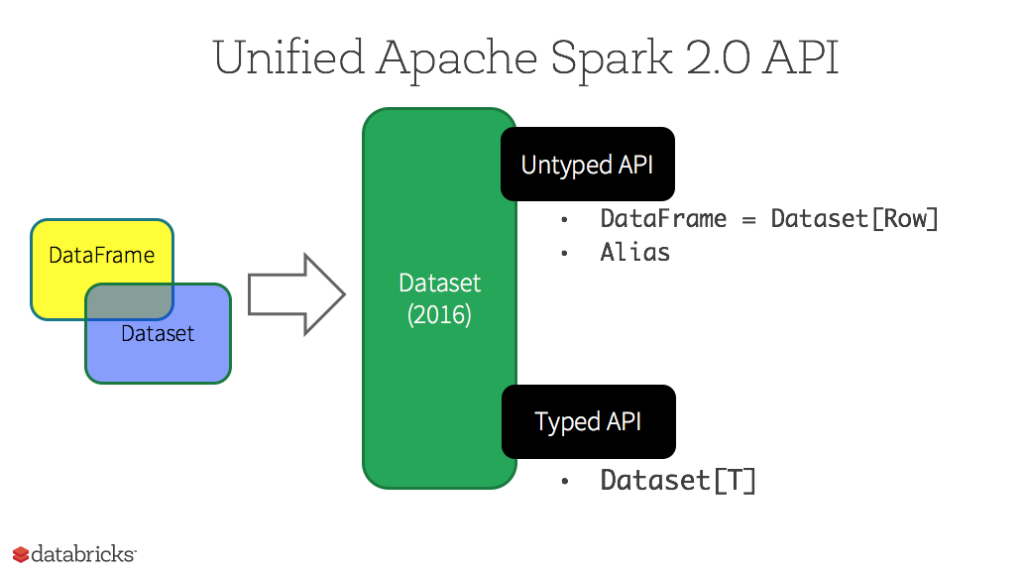
在 Spark 2.0 中,DataSet 整合了 DataFrame 的功能,DataFrame 被表示为 DataSet[Row]。
![RDD_DataFrame_Dataset]()
RDD、DataFrame 和 Dataset 的区别和应用场景?
![SparkAPIs发展史]()
Spark API 的发展史:RDD(Spark 1.0) -> DataFrame(Spark 1.3) -> Dataset(Spark 1.6)。在 Spark 2.0 中,DataFrame 和 Dataset 的 API 融合到一起,通过一套名为 Dataset 的高级并且类型安全的API完成跨函数库的数据处理能力。DataFrame 成为 Dataset 的特例,DataFrame = Dataset[Row]。
![Dataset_DataFrame_RDD]()
Spark Core 提供 RDD 作为面向用户的主要 API,一个 RDD 就是数据的一个不可变的分布式集合,在集群中跨节点分布,可以通过若干提供了转换和处理的底层 API 进行并行处理。
RDD 的使用场景和常见案例:
- 需要数据集进行最基本的转换、处理和控制;
- 数据是非结构化的,比如流媒体或者字符流;
- 想通过函数式编程而不是领域特定语言(DSL)来处理数据;
- 不希望像列式处理一样定义一个模式,通过名字或字段来处理或访问数据属性;
- 不在意 DataFrame 和 Dataset 在处理结构化和半结构化数据时提供的优化和性能上的好处;
Spark SQL 提供的 DataFrame 也是数据的一个不可变的分布式集合。但与 RDD 不同的是,数据都被组织到有名字的列中,就像关系型数据库中的表一样。设计 DataFrame 的目的就是要让对大型数据集的处理变得更简单,它让开发者可以为分布式的数据集指定一个模式,进行更高层次的抽象。
![Dataset]()
从 Spark 2.0 开始,Dataset 开始具有两种不同类型的 API 特征:有明确类型的 API 和无类型的 API。可以把 DataFrame 当作 Dataset[Row] 的别名,一行就是一个通用的无类型的 JVM 对象。与之形成对比,Dataset 就是一些有明确类型定义的 JVM 对象的集合,通过在 Scala 中定义的样例类来指定类型。
![类型安全图谱]()
相比 DataFrame 和 SQL,Dataset 提供了编译时类型检查,所有不匹配的类型参数和分析错误都可以在编译时发现,这样就节省了开发者的时间和代价。因为对于分布式程序来说,提交一次作业太麻烦了(编译、打包、上传、运行),这也是引入 Dataset 的一个重要原因。
创建 DataFrame
在 Spark2.0 之前,Spark SQL 提供的 SQLContext 是创建 DataFrame 和执行 SQL 的入口,可以利用继承了 SQLContext 的 hiveContext 通过 HiveQL 语句操作 Hive 数据。在 Spark2.0 之后,SparkSession 封装了 SparkContext 和 SQLContext,通过 SparkSession 可以获取到 SparkConetxt 和 SQLContext 对象。
数据源为文本文件
准备文本文件 employee.txt:
employee.txt1
2
3
| 1 zhangsan 23
2 lisi 24
3 wangwu 25
|
方式一:RDD + 样例类
/export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| # 启动Spark
# bin/spark-shell --master local[2]
scala> val lineRDD = sc.textFile("file:///export/data/employee.txt").map(x => x.split(" "))
lineRDD: org.apache.spark.rdd.RDD[Array[String]] = MapPartitionsRDD[2] at map at <console>:24
scala> case class Employee(id:Int,name:String,age:Int)
defined class Employee
scala> val employeeRDD = lineRDD.map(x => Employee(x(0).toInt,x(1),x(2).toInt))
employeeRDD: org.apache.spark.rdd.RDD[Employee] = MapPartitionsRDD[3] at map at <console>:28
scala> val employeeDF = employeeRDD.toDF
employeeDF: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more field]
scala> employeeDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| lisi| 24|
| 3| wangwu| 25|
+---+--------+---+
scala> employeeDF.printSchema
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
employeeDF.rdd.collect
|
方式二:通过 SparkSession 直接构建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| scala> val employeeDF2 = spark.read.text("file:///export/data/employee.txt")
employeeDF2: org.apache.spark.sql.DataFrame = [value: string]
scala> employeeDF2.show
+-------------+
| value|
+-------------+
|1 zhangsan 23|
| 2 lisi 24|
| 3 wangwu 25|
+-------------+
scala> employeeDF2.printSchema
root
|-- value: string (nullable = true)
|
数据源为json文件
直接解析 json 数据创建 DataFrame:
1
2
3
4
5
6
7
8
9
10
11
| scala> val peopleDF = spark.read.json("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
|
数据源为parquet文件
parquet 是一种列式存储格式。直接解析 parquet 数据创建 DataFrame:
1
2
3
4
5
6
7
8
9
10
| scala> val userDF = spark.read.parquet("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/users.parquet")
userDF: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field]
scala> userDF.show
+------+--------------+----------------+
| name|favorite_color|favorite_numbers|
+------+--------------+----------------+
|Alyssa| null| [3, 9, 15, 20]|
| Ben| red| []|
+------+--------------+----------------+
|
DataFrame常用操作
使用DSL
DataFrame 提供了一个领域特定语言(DSL)来操作结构化数据。
全查询
查看 DataFrame 中的内容:
1
2
3
4
5
6
7
8
| scala> employeeDF.show
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| lisi| 24|
| 3| wangwu| 25|
+---+--------+---+
|
查看表结构
查看 DataFrame 中的 Schema:
1
2
3
4
5
6
7
8
| scala> employeeDF.schema
res0: org.apache.spark.sql.types.StructType = StructType(StructField(id,IntegerType,false), StructField(name,StringType,true), StructField(age,IntegerType,false))
scala> employeeDF.printSchema
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
|
查询
查询 DataFrame 中字段的值:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
|
scala> employeeDF.select(employeeDF.col("name")).show
scala> employeeDF.select("name").show
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| wangwu|
+--------+
scala> employeeDF.select(col("name"),col("age")).show
scala> employeeDF.select("name","age").show
scala> employeeDF.select($"name",$"age").show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 23|
| lisi| 24|
| wangwu| 25|
+--------+---+
scala> employeeDF.select(col("id"), col("name"), col("age") + 1).show
scala> employeeDF.select(employeeDF("id"), employeeDF("name"), employeeDF("age") + 1).show
+---+--------+---------+
| id| name|(age + 1)|
+---+--------+---------+
| 1|zhangsan| 24|
| 2| lisi| 25|
| 3| wangwu| 26|
+---+--------+---------+
scala> employeeDF.filter(col("age") > 23).show
+---+------+---+
| id| name|age|
+---+------+---+
| 2| lisi| 24|
| 3|wangwu| 25|
+---+------+---+
scala> employeeDF.filter(col("age")>23).count
res14: Long = 2
scala> employeeDF.groupBy("age").count().show
+---+-----+
|age|count|
+---+-----+
| 23| 1|
| 25| 1|
| 24| 1|
+---+-----+
|
使用SQL
可以将 DataFrame 看作是一个关系型数据表,通过在 sql() 方法执行 SQL 语句,结果返回一个 DataFrame。Spark SQL 支持的 SQL 语法是 HiveQL 的超集。SQL 解析器使用 ANTLRv4 编写,可以在源码中查看语法文件 SqlBase.g4 。
注册数据表
想要使用 SQL 语法,需要先将 DataFrame 注册成表:
1
| scala> employeeDF.registerTempTable("t_employee")
|
查看表结构
查看 t_employee 表的描述信息:
1
2
3
4
5
6
7
8
| scala> spark.sql("desc t_employee").show
+--------+---------+-------+
|col_name|data_type|comment|
+--------+---------+-------+
| id| int| null|
| name| string| null|
| age| int| null|
+--------+---------+-------+
|
查询
查询年龄最大的前两名员工的信息:
1
2
3
4
5
6
7
| scala> spark.sql("select * from t_employee order by age desc limit 2").show
+---+------+---+
| id| name|age|
+---+------+---+
| 3|wangwu| 25|
| 2| lisi| 24|
+---+------+---+
|
创建Dataset
createDataset
用法一:通过集合创建
1
2
3
4
5
6
7
8
9
10
11
| scala> val ds1 = spark.createDataset(1 to 3)
ds1: org.apache.spark.sql.Dataset[Int] = [value: int]
scala> ds1.show
+-----+
|value|
+-----+
| 1|
| 2|
| 3|
+-----+
|
用法二:通过 RDD 创建
1
2
3
4
5
6
7
8
9
10
11
| scala> val ds2 = spark.createDataset(sc.textFile("file:///export/data/employee.txt"))
ds2: org.apache.spark.sql.Dataset[String] = [value: string]
scala> ds2.show
+-------------+
| value|
+-------------+
|1 zhangsan 23|
| 2 lisi 24|
| 3 wangwu 25|
+-------------+
|
toDS
用法一:通过样例类转换
1
2
3
4
5
6
7
8
9
10
11
12
| scala> case class Person(name:String,age:Int)
scala> val personDataList = List(Person("zhangsan",23),Person("lisi",24))
scala> val personDS = personDataList.toDS
personDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: int]
scala> personDS.show
+--------+---+
| name|age|
+--------+---+
|zhangsan| 18|
| lisi| 28|
+--------+---+
|
用法二:通过 RDD 转换
1
| val ds3 = sc.textFile("file:///export/data/employee.txt").toDS
|
as[ElementType]
通过 as[ElementType] 将 DataFrame 转换为 Dataset:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| scala> case class Person(name:String,age:Long)
defined class Person
scala> val peopleDF = spark.read.json("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/people.json")
jsonDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> val peopleDS = peopleDF.as[Person]
peopleDS: org.apache.spark.sql.Dataset[Person] = [age: bigint, name: string]
scala> peopleDS.show
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
|
RDD、DataFrame、Dataset相互转换
DataFrame 与 DataSet 相互转化:
- DataFrame -> Dataset:
df.as[ElementType]。
- Dataset -> DataFrame:
ds.toDF。
Dataset 与 RDD 相互转换:
- DataSet -> RDD:
ds.rdd
- RDD -> DataSet:
rdd.toDS
RDD 与 DataFrame 相互转换:
- RDD -> DataFrame:
rdd.toDF
- DataFrame -> RDD:
df.rdd
编程执行 SparkSQL
//TODO
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| ===================使用DSL语法操作===========================
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
|-- age: integer (nullable = false)
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
| 2| lisi| 34|
| 3| Monica| 27|
+---+--------+---+
only showing top 3 rows
+--------+
| name|
+--------+
|zhangsan|
| lisi|
| Monica|
| Joey|
| Ross|
|Chandler|
| Rachel|
| Phoebe|
+--------+
+---+--------+---+
| id| name|age|
+---+--------+---+
| 2| lisi| 34|
| 5| Ross| 31|
| 6|Chandler| 31|
+---+--------+---+
+---+-----+
|age|count|
+---+-----+
| 31| 2|
| 34| 1|
| 28| 1|
| 27| 2|
| 23| 1|
| 25| 1|
+---+-----+
===================使用SQL语法操作===========================
+---+--------+---+
| id| name|age|
+---+--------+---+
| 1|zhangsan| 23|
+---+--------+---+
+---+--------+---+
| id| name|age|
+---+--------+---+
| 2| lisi| 34|
| 5| Ross| 31|
| 6|Chandler| 31|
+---+--------+---+
|
参考资料
且谈 Apache Spark 的 API 三剑客:RDD、DataFrame 和 Dataset 作者:Jules Damji,译者:足下